基础安装
yum -y install epel-release
yum -y install iptables-services
# 关闭selinux
sed -i 's/SELINUX=enforcing/SELINUX=disabled/g' /etc/selinux/config
setenforce 0
# 关闭firewalld
systemctl stop firewalld
systemctl disable firewalld
在CentOS 7上编译内核支持IPSec,您可以按照以下步骤操作:
1.下载内核源代码:
```bash
sudo yum groupinstall "Development Tools" -y
sudo yum install openssl-devel -y
sudo yum install kernel-devel -y
uname -r
3.10.0-1160.62.1.el7.x86_64
wget https://cdn.kernel.org/pub/linux/kernel/v3.x/linux-3.10.tar.gz
tar -xzvf linux-3.10.tar.gz
cd linux-3.10
```
2.配置内核选项:
```bash
make menuconfig
```
在menuconfig中,您需要找到以下选项并启用它们:
- Networking support -> Networking options -> TCP/IP networking -> IPsec support
- IPv6: IPsec tunnel support
- Cryptographic API -> AES cipher algorithms
- Cryptographic API -> SHA1 digest algorithm
- Cryptographic API -> HMAC support
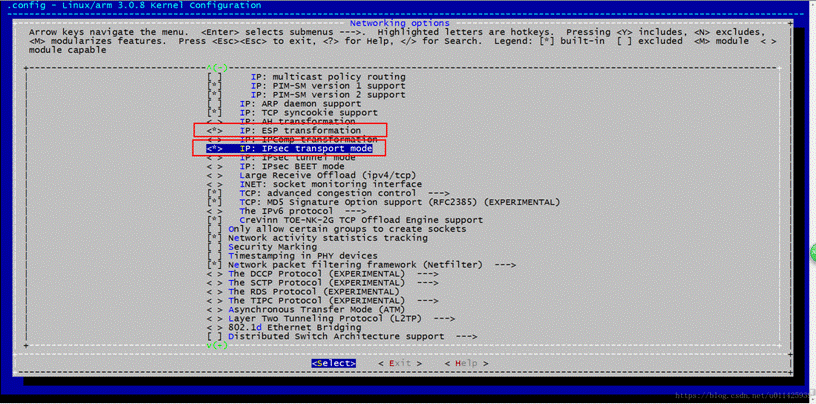
保存配置并退出。
3.编译内核:
```bash
make
```
4.安装新内核:
```bash
sudo make modules_install install
```
5.重新启动系统并选择新编译的内核。
现在,您的CentOS 7系统已经编译支持IPSec的内核。您可以配置和使用IPSec来加密和保护网络通信。
Strongswan是一个开源的IPsec实现,CentOS 7中安装Strongswan 5.9.13版本可以按照以下步骤进行:
1. 首先,确认系统中已经安装了所需的依赖包:
```
sudo yum install epel-release
sudo yum install gcc make perl openssl-devel libcurl-devel wget
```
2. 下载Strongswan 5.9.13版本的源码包:
```
wget https://download.strongswan.org/strongswan-5.9.13.tar.gz
```
3. 解压源码包并进入解压后的目录:
```
tar -zxvf strongswan-5.9.13.tar.gz
cd strongswan-5.9.13
```
4. 编译和安装Strongswan:
```
./configure --prefix=/usr/strongswan/ --sysconfdir=/etc/strongswan/ --enable-eap-dynamic --enable-eap-identity --enable-eap-md5 --enable-eap-mschapv2 --enable-eap-tls --enable-eap-ttls --enable-eap-tnc --enable-eap-aka --enable-eap-aka-3gpp2 --enable-eap-sim --enable-eap-sim-file --enable-eap-simaka-pseudonym --enable-eap-simaka-reauth --enable-eap-simaka-pseudonym --enable-eap-simaka-reauth --enable-eap-peap --enable-eap-tls --enable-eap-tnc --enable-eap-dynamic --enable-tls --enable-xauth-eap --enable-certexpire --enable-radattr --enable-gcrypt
make && make install
sudo make install
```
5. 配置Strongswan的IPsec:
```
sudo cp -r /usr/strongswan/etc/ipsec.conf.sample /etc/strongswan/ipsec.conf
sudo cp -r /usr/strongswan/etc/ipsec.secrets.sample /etc/strongswan/ipsec.secrets
sudo cp -r /usr/strongswan/etc/strongswan.conf.sample /etc/strongswan/strongswan.conf
```
6. 启动Strongswan服务:
```
sudo systemctl start strongswan
```
至此,Strongswan 5.9.13版本已经成功安装并启动在CentOS 7系统中。您可以根据需要进一步配置和使用Strongswan的功能。
Iptables设置
```
# Generated by iptables-save v1.4.21 on Thu Feb 29 15:26:18 2024
*mangle
:PREROUTING ACCEPT [8351:4045050]
:INPUT ACCEPT [8351:4045050]
:FORWARD ACCEPT [0:0]
:OUTPUT ACCEPT [10452:2403987]
:POSTROUTING ACCEPT [10452:2403987]
-A FORWARD -m policy --pol ipsec --dir in -p tcp -m tcp --tcp-flags SYN,RST SYN -m tcpmss --mss 1361:1536 -j TCPMSS --set-mss 1360
-A FORWARD -m policy --pol ipsec --dir out -p tcp -m tcp --tcp-flags SYN,RST SYN -m tcpmss --mss 1361:1536 -j TCPMSS --set-mss 1360
COMMIT
# Completed on Thu Feb 29 15:26:18 2024
# Generated by iptables-save v1.4.21 on Thu Feb 29 15:26:18 2024
*nat
:PREROUTING ACCEPT [4:168]
:INPUT ACCEPT [0:0]
:OUTPUT ACCEPT [11:664]
:POSTROUTING ACCEPT [11:664]
-A POSTROUTING -s 192.168.88.0/24 -o ens3 -m policy --dir out --pol ipsec -j ACCEPT
-A POSTROUTING -s 192.168.88.0/24 -o ens3 -j MASQUERADE
-I POSTROUTING -m policy --pol ipsec --dir out -j ACCEPT
COMMIT
# Completed on Thu Feb 29 15:26:18 2024
# Generated by iptables-save v1.4.21 on Thu Feb 29 15:26:18 2024
*filter
:INPUT ACCEPT [0:0]
:FORWARD ACCEPT [0:0]
:OUTPUT ACCEPT [379:79472]
-A INPUT -m state --state RELATED,ESTABLISHED -j ACCEPT
-A INPUT -p icmp -j ACCEPT
-A INPUT -i lo -j ACCEPT
-A INPUT -p tcp -m state --state NEW -m tcp --dport 22 -j ACCEPT
-A INPUT -p tcp -m multiport --dports 843,587,465,25 -j ACCEPT
-A INPUT -p tcp -m state --state NEW -m tcp --dport 21 -j ACCEPT
-A INPUT -p tcp -m state --state NEW -m tcp --dport 53 -j ACCEPT
-A INPUT -p tcp -m state --state NEW -m tcp --dport 25 -j ACCEPT
-A INPUT -p tcp -m state --state NEW -m tcp --dport 110 -j ACCEPT
-A INPUT -p tcp -m state --state NEW -m tcp --dport 80 -j ACCEPT
-A INPUT -p tcp -m state --state NEW -m tcp --dport 139 -j ACCEPT
-A INPUT -p tcp -m state --state NEW -m tcp --dport 443 -j ACCEPT
-A INPUT -p tcp -m state --state NEW -m tcp --dport 445 -j ACCEPT
-A INPUT -p udp -m udp --dport 53 -m conntrack --ctstate NEW -j ACCEPT
-A INPUT -p tcp -m tcp --dport 22 -m conntrack --ctstate NEW -j ACCEPT
-A INPUT -p tcp -m tcp --dport 1723 -m conntrack --ctstate NEW -j ACCEPT
-A INPUT -p tcp -m tcp --dport 47 -m conntrack --ctstate NEW -j ACCEPT
-A INPUT -p udp -m udp --dport 500 -j ACCEPT
-A INPUT -p udp -m udp --dport 4500 -j ACCEPT
-A INPUT -j REJECT --reject-with icmp-host-prohibited
#-A FORWARD -s 192.168.88.0/24 -j ACCEPT
-A FORWARD -i ens3 -j ACCEPT
-A FORWARD -j REJECT --reject-with icmp-host-prohibited
COMMIT
# Completed on Thu Feb 29 15:26:18 2024
```
创建证书过程中的参数说明
--ca 创建ca
--lifetime 证书有效期,默认天
--type 类型
--size 长度
--dn 提取 X.509 证书的主题 DN
--gen 生成一个新的私钥
--issue 使用 CA 证书和密钥颁发证书
--pub 从私钥/证书中提取公钥
--self 创建自签名证书
#######
--cakey CA的秘钥
--cacert CA的证书
--san 包含在证书中ubjectAltName的扩展
--flag 添加extendedKeyUsage标志
--outform 生成的证书编码
使用strongswan创需要的证书文件(文件名自己定义就好)
# 先创建一个临时目录,放证书文件
mkdir cert && cd cert
# 创建ca秘钥
strongswan pki --gen --type rsa --size 4096 --outform pem > ca.haose888.net-key.pem
# 创建ca证书("C=,O=,CN=",这里面内容自定义就好)
strongswan pki --self --ca --lifetime 3650 --in ca.haose888.net-key.pem --type rsa --dn "C=CN,O=haose888.net,CN=haose888.net" --outform pem > ca.haose888.net.cer
# 创建服务端秘钥
strongswan pki --gen --type rsa --size 4096 --outform pem > server.haose888.net-key.pem
# 创建服务端公钥
strongswan pki --pub --in server.haose888.net-key.pem --outform pem > server.haose888.net-pub.pem
# 创建服务端证书(注意:这里--dn参数内容要和上面的对应,--san 要修改为你的服务器域名或者公网ip,我这里使用域名)
strongswan pki --pub --in server.haose888.net-key.pem | strongswan pki \
--issue \
--lifetime 3650 \
--cakey ca.haose888.net-key.pem \
--cacert ca.haose888.net.cer \
--dn "C=CN,O=haose888.net,CN=haose888.net" \
--san="haose888.net" \
--flag serverAuth \
--flag ikeIntermediate \
--outform pem > server.haose888.net-cert.pem
复制生成的证书文件到对应的目录中
cp ca.haose888.net.cer /etc/strongswan/ipsec.d/cacerts/
cp ca.haose888.net-key.pem /etc/strongswan/ipsec.d/private/
cp server.haose888.net-key.pem /etc/strongswan/ipsec.d/private/
cp server.haose888.net-cert.pem /etc/strongswan/ipsec.d/certs/
cp server.haose888.net-pub.pem /etc/strongswan/ipsec.d/certs/
修改配置/etc/strongswan/ipsec.conf文件,经测试win10和ios系统都可以正常连接使用
配置中的文件名要和你创建的一致
协商协议可自定义
分配的客户端的虚拟ip网段可以自定义
dns看情况自定义)
config setup
# 是否严格执行证书吊销规则
#strictcrlpolicy=yes
# 如果同一个用户在不同的设备上重复登录,yes 断开旧连接,创建新连接;no 保持旧连接,并发送通知;never 同 no,但不发送通知。
uniqueids = no
######################
# 公用配置 #
######################
conn %default
# 是否启动压缩
compress = yes
# 数据传输协议加密算法列表,对于IKEv2,可以在包含相同类型的多个算法(这个我复制别人的)
ike = aes256-sha256-modp1024,3des-sha1-modp1024,aes256-sha1-modp1024!
# 断开连接的操作,hold表示保持到重连直到超时,clear表示清除
dpdaction = clear
# 断开后重新连接时长
dpddelay = 30s
# 断开连接后超时时长,只对IKEv1有用
dpdtimeout = 60s
# 空闲时长,吵过后断开连接
inactivity = 300s
# 指定服务端与客户端的 DNS,多个用“,”分隔(看你服务器在哪,dns就修改为对应的)
leftdns = 8.8.8.8
rightdns = 8.8.8.8
# 你服务端ip
left = %any
# 客户端ip
right = %any
conn IKE-BASE
# 服务器端根证书DN名称
leftca = "C=CN, O=haose888.net, CN= haose888.net"
# 是否发送服务器证书到客户端
leftsendcert = always
# 客户端不发送证书
rightsendcert = never
# 服务器端证书
leftcert = server.haose888.net-cert.pem
# 客户端分配的虚拟IP地址段
rightsourceip=192.168.88.0/24
###########################################################
# win10可用 | 苹果手机使用IKEv2模式(需要手机上安装证书) #
###########################################################
conn IKEv2
also = IKE-BASE
# 密钥交换协议加密算法列表,可以包括多个算法和协议
esp = aes256-sha256,3des-sha1,aes256-sha1!
# 使用ikev2
keyexchange = ikev2
# 服务端ip,可以是%any,表示从本地ip中取
left = %any
# 服务器端虚拟ip子网,0.0.0.0/0表示通配
leftsubnet = 0.0.0.0/0
# 客户端ip,%any表示任意
right = %any
# 服务端校验方式,使用证书
leftauth=pubkey
# 客户端认证使用 EAP 扩展认证, EAP(Username/Password)
rightauth=eap-mschapv2
# 服务端ID (和上面创建服务端证书时一致(--san指定的内容),这里使用域名)
leftid = haose888.net
# 客户端 id,任意
rightid = %any
# 不自动重置密钥
rekey = no
# 指定客户端eap id
eap_identity = %any
# 当服务启动时, 应该如何处理这个连接项,add 添加到连接表中
auto = add
# 开启 IKE 消息分片
fragmentation=yes
#############################################
# Android ipsec xuauth psk | IOS ipsec #
#############################################
conn IPSec-IKEv1-PSK
also=IKE-BASE
esp=aes256-sha256_96,3des-sha1,aes256-sha1!
keyexchange=ikev1
fragmentation=yes
leftauth=psk
rightauth=psk
rightauth2=xauth
auto=add
修改/etc/strongswan/ipsec.secrets配置文件,配置认证秘钥和用户密码(这个配置我看别人的)
# ipsec.secrets - strongSwan IPsec secrets file
# 使用证书验证时的服务器端私钥
: RSA server.haose888.net-key.pem
# 预设psk秘钥
: PSK "123456"
# XAUTH 方式, 只适用于 IKEv1
vpnuser : XAUTH "123456"
# EAP 方式,用户和密码
vpnuser : EAP "123456"
开启内核转发
echo "net.ipv4.ip_forward = 1" >> /etc/sysctl.conf
sysctl -p
启动strongswan服务
# 启动(如果参数配置有误,这里有提示的)
systemctl start strongswan-starter.service
# 停止
systemctl stop strongswan-starter.service
# 重启
systemctl restart strongswan-starter.service
# 查看状态
systemctl status strongswan-starter.service
测试连通
ping -c 4 -I ens3 haose888.net
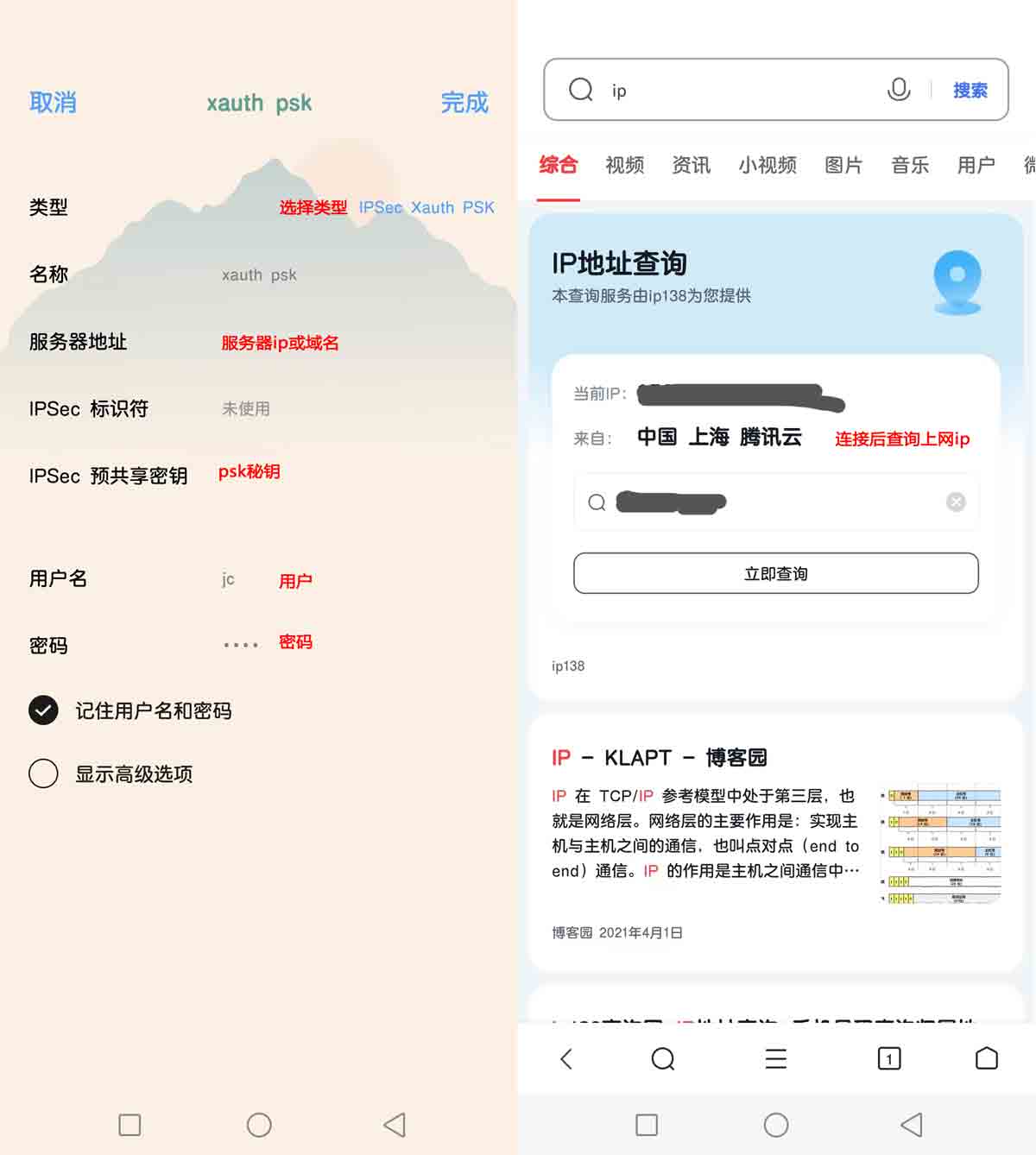
使用安卓连接,使用ipsec xauth psk 方式
我手机自带的ikev2有bug用不了,只能用这个ipsec方式测试;而且还遇到 Android 设备有 MTU/MSS 问题,表现为使用 IPsec/XAuth ("Cisco IPsec") 模式可以连接到 VPN 但是无法打开网站。需要在服务器上加上iptables规则才能解决
# 解决安卓使用ipsec/xauth 方式连接后上不了网(这是看到别人的解决办法,经测试确实可以解决)
iptables -t mangle -A FORWARD -m policy --pol ipsec --dir in -p tcp -m tcp --tcp-flags SYN,RST SYN -m tcpmss --mss 1361:1536 -j TCPMSS --set-mss 1360
iptables -t mangle -A FORWARD -m policy --pol ipsec --dir out -p tcp -m tcp --tcp-flags SYN,RST SYN -m tcpmss --mss 1361:1536 -j TCPMSS --set-mss 1360
# 该文件表示在全局范围内关闭路径MTU探测功能
echo "net.ipv4.ip_no_pmtu_disc = 1">> /etc/sysctl.conf
sysctl –p
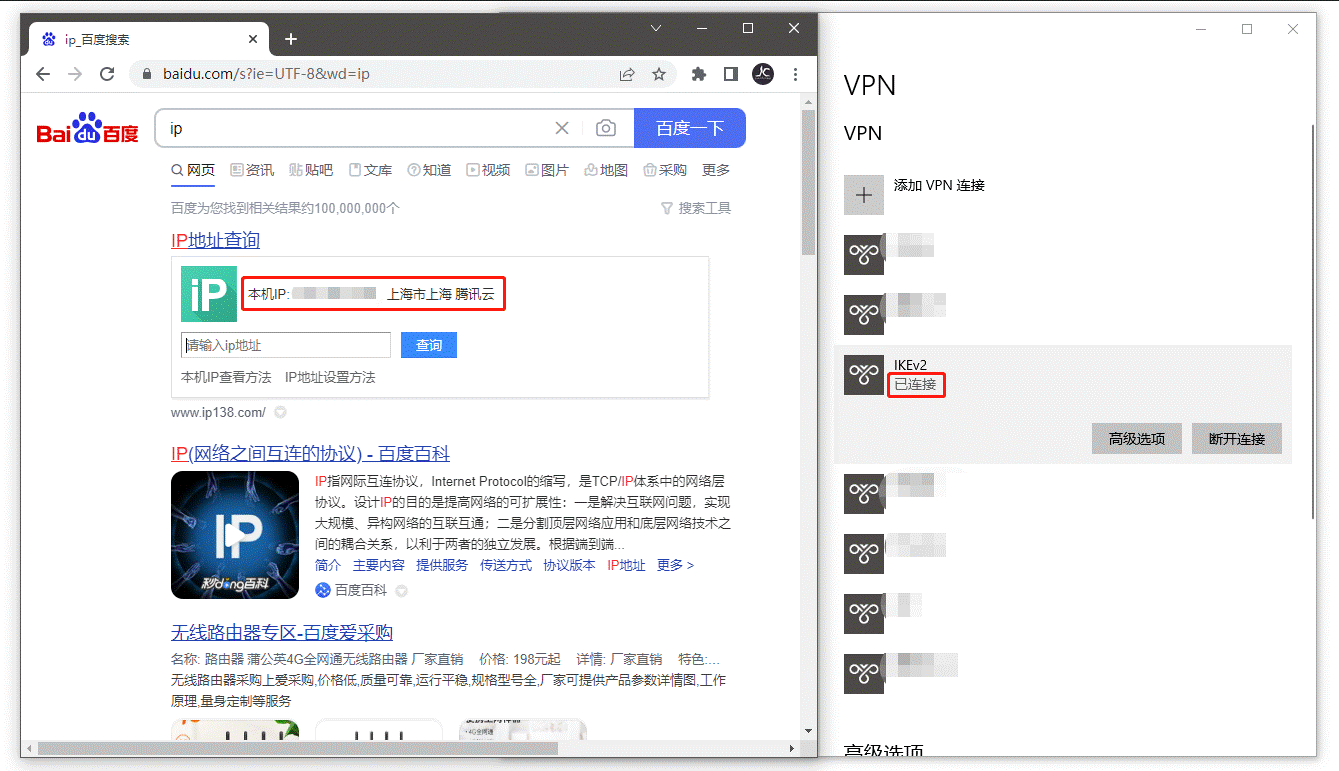
使用win10系统连接
需要先把ca证书(ca.haose888.net.cer证书文件)下载下来,安装到系统里面
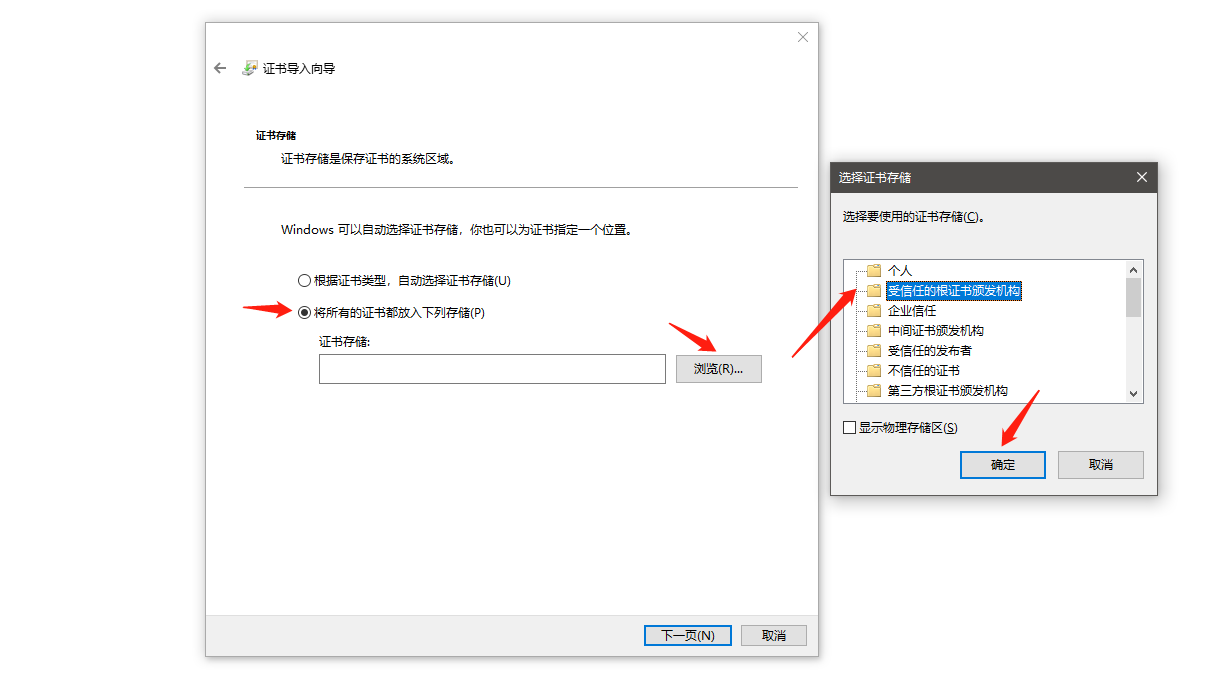
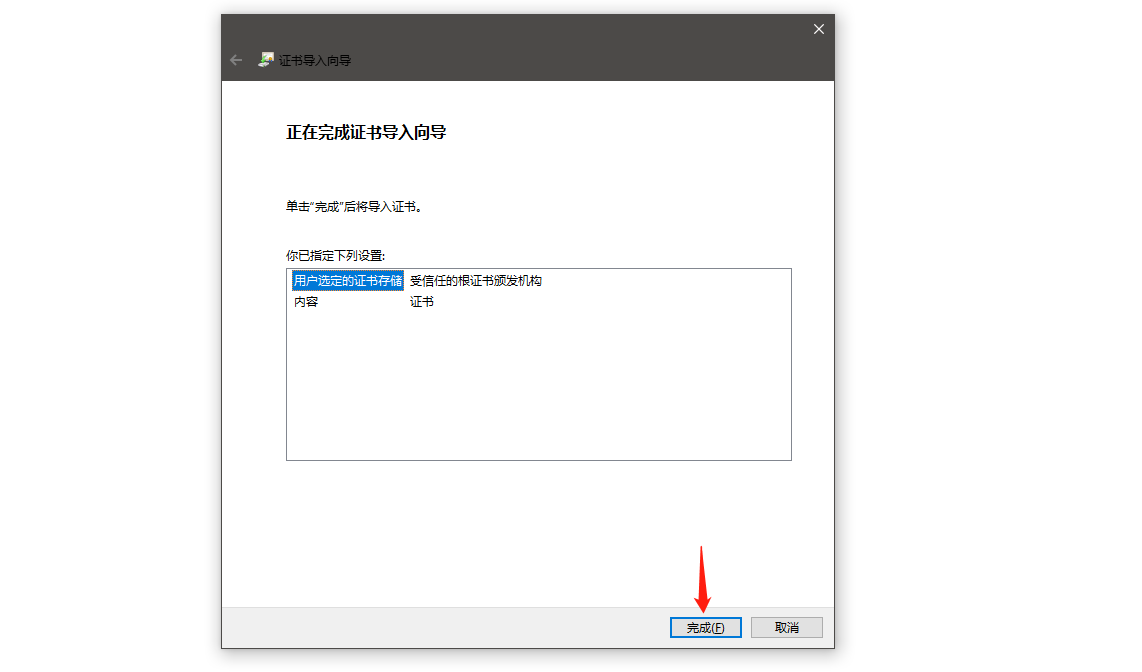
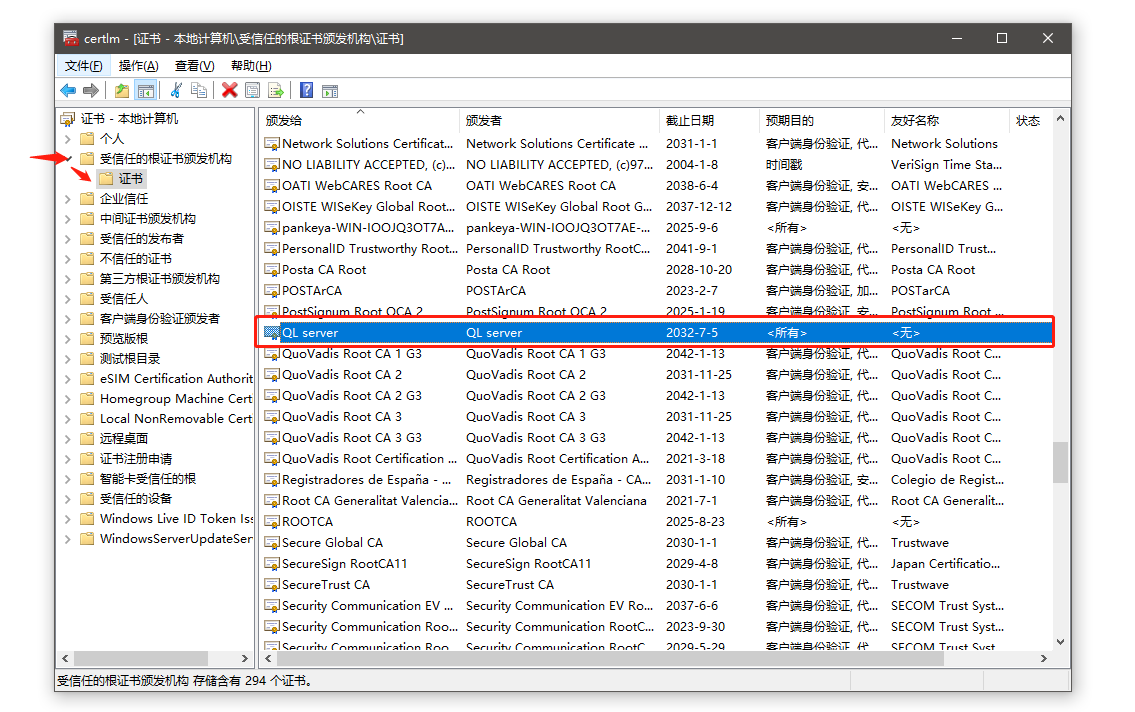
新建一个vpn连接,选择IKEv2,写上用户和密码
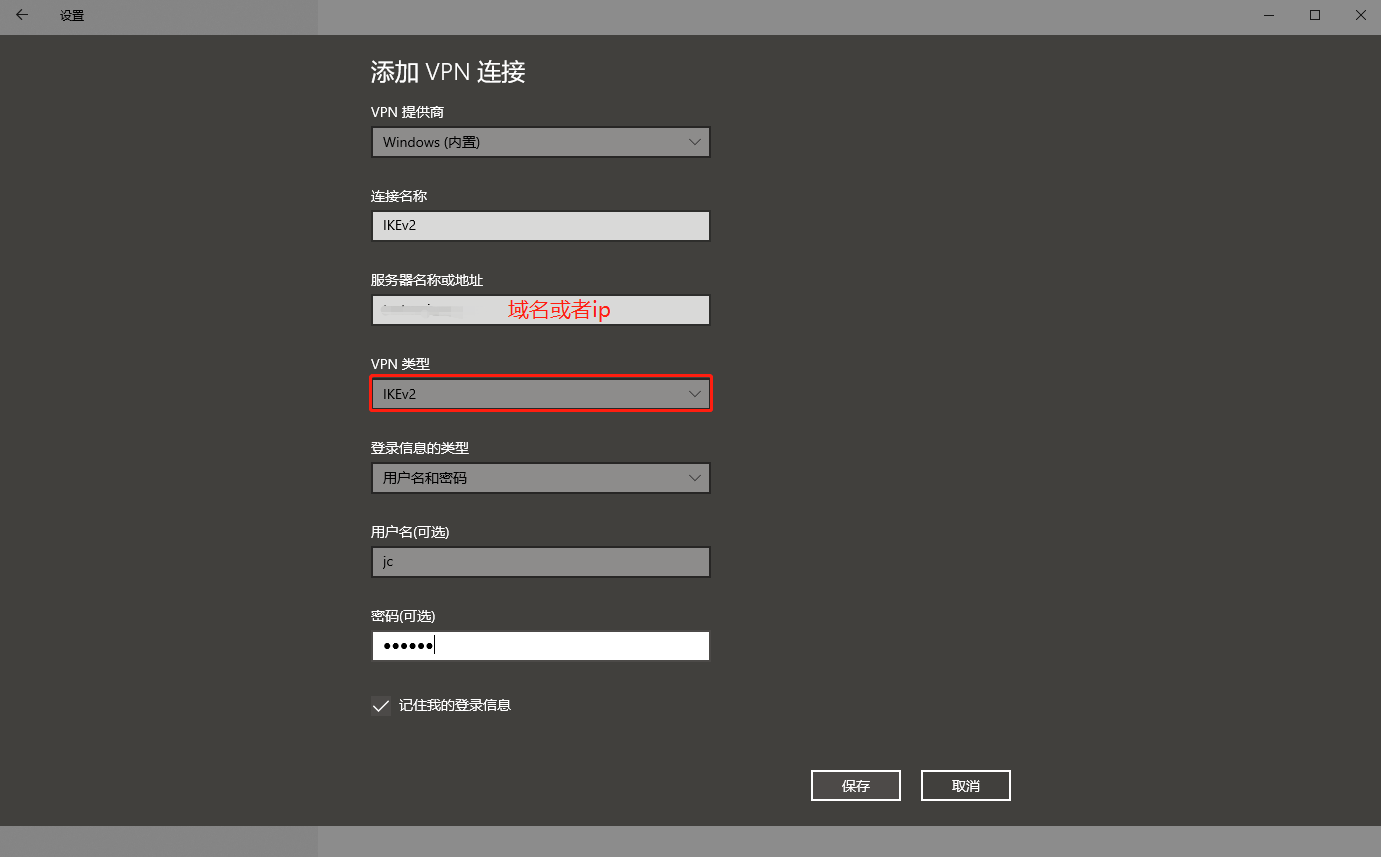
有个注意的地方,下面图中的红框文字的说明
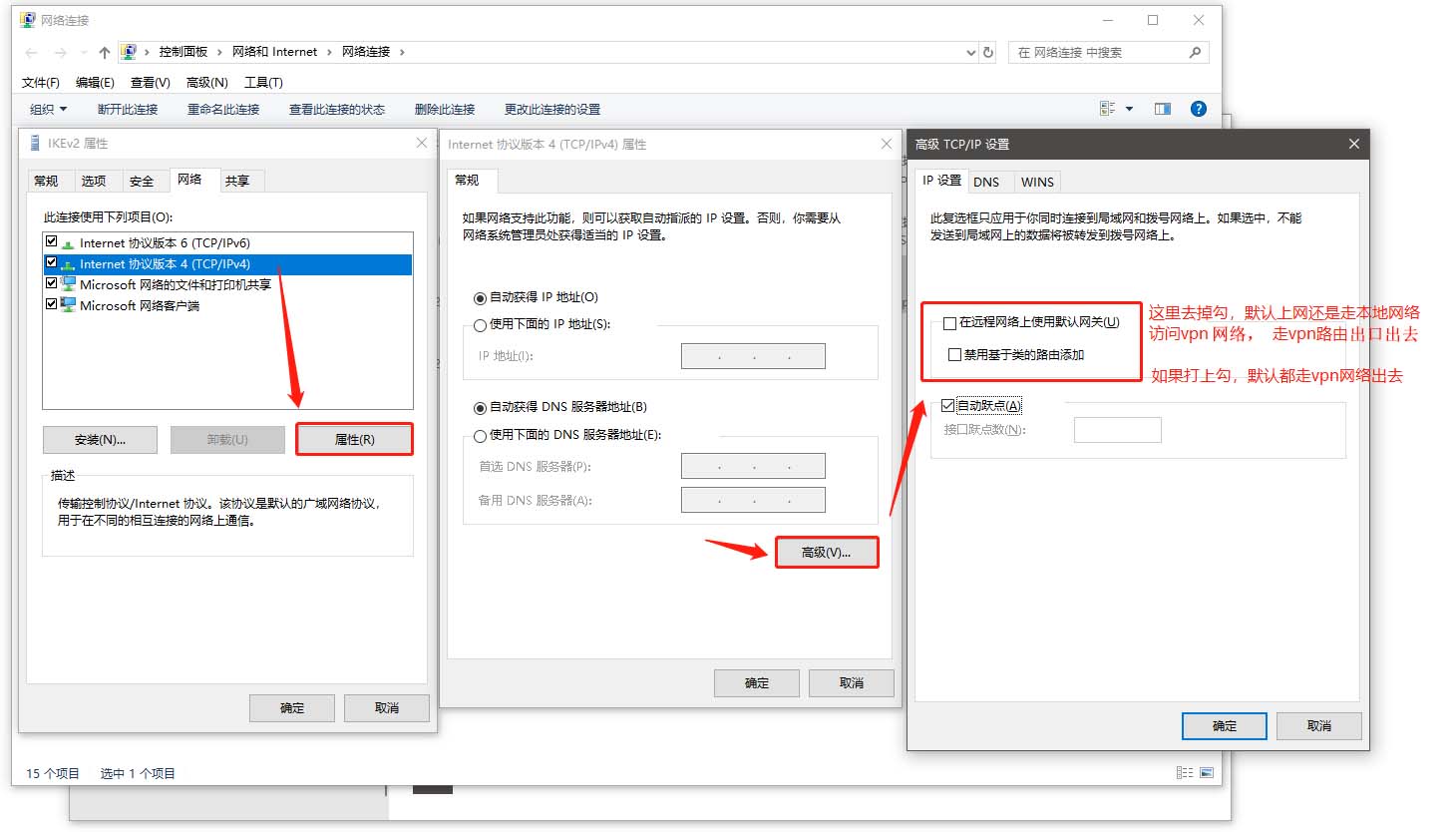
连接到服务器成功,查看出口ip(如果看到ip还是本地默认的,说明上图中的那个没勾选,勾选后看到的就是vpn的网络地址了)